Nous pourrions résumer l’écriture à une suite de symboles. Ces formes, nommées “caractères”, regroupent tous les alphabets du monde, les chiffres, la ponctuation et même les emojis 😄.
Dans cet article, nous allons nous intéresser à comment sont représentés les caractères dans l’informatique. Comme toutes données informatisées, les caractères sont représentés par une suite de zéros et de uns et affichés sous forme graphique pour que nous ne nous y perdions pas. Cependant, la façon d’ordonner les zéros et les uns dépend de l’encodage utilisé.
Fait surprenant, l’encodage n’est pas présent en tant que métadonnée d’un fichier (comme l’est le titre, ou la date de création). Le seul moyen de le connaître est… de le deviner ! Oui vous avez bien lu, quelque chose qui devrait être basique est en fait un vrai plat de spaghettis où chacun utilise des normes différentes. Nous allons démêler tout cela ci-dessous.
Pour cela, nous devons nous équiper d’un terminal capable de comprendre plusieurs encodages. Sous macOS, l’application native Terminal permet de le faire. Sinon, la commande *nix iconv permet de traduire d’un encodage à un autre.
Au début, l’ASCII
Au début des années soixante, les caractères étaient codés sur sept bits ! Nous pouvions donc représenter 2^7 = 128 caractères différents. L’informatique étant principalement en anglais, il y avait largement la place pour y représenter tout l’alphabet latin en majuscule et en minuscule, plus les chiffres et autres caractères de ponctuation.
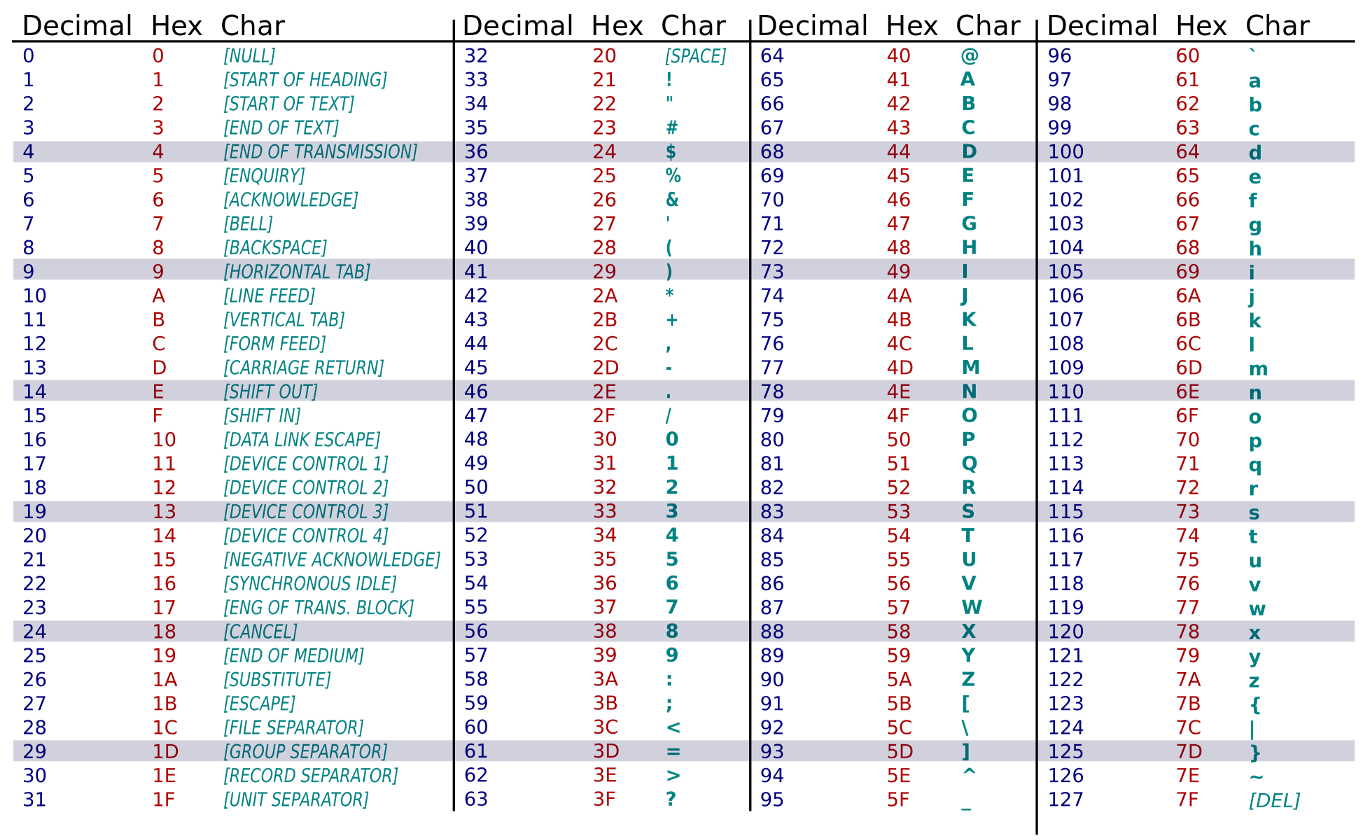 Les cent vingt-huit caractères de la table ASCII.
Les cent vingt-huit caractères de la table ASCII.
Le terme officiel pour décrire cet encodage est us-ascii ou encore iso646. Cet encodage est simple, chaque caractère tient sur un octet. Parcourir un fichier est aisé, chaque octet lu peut être représenté graphiquement !
Créons une séquence ASCII à la main :
# terminal en us-ascii
$ echo -ne '\x61\x62\x63' > ascii
$ cat ascii
abc
Seulement voilà, cet alphabet n’en est qu’un parmi trois milles autres1. Il a donc fallu trouver un moyen de pouvoir représenter ces autres alphabets.
L’ASCII étendu
Avant toute chose, l’ASCII étendu n’existe pas. C’est un regroupement de différents encodages basés sur le même principe. L’ASCII se représente sur sept bits, mais un octet contient huit bits, après calcul, il reste un bit qui n’est pas utilisé ! Grâce à celui-ci, c’est cent vingt-huit nouveaux caractères qui peuvent être créés !
Je vous présente les encodages iso-8859-1, iso-8859–2, iso-8859-3, iso-8859-4, iso-8859-5, iso-8859-6, iso-8859-7, iso-8859-8, iso-8859-9, iso-8859-10, iso-8859-11, iso-8859-12, iso-8859-13, iso-8859-14, iso-8859-15. Ça en fait !
Le principe est de garder les caractères ASCII et d’ajouter les caractères manquant dans les cent vingt huit restants. Chaque norme correspond donc à une combinaison d’alphabets. Par exemple, l’encodage iso-8859–7 contient les caractères latins et les caractères grecs. L’encodage iso-8859-15 contient les caractères latins et les caractères manquants des langues européennes.
Ceci implique qu’un même fichier peut être lu différemment selon l’encodage utilisé pour décoder, exemple :
$ echo -ne '\x34\x32\xa5' > ambiguous
Je configure mon terminal pour afficher les caractères en iso-8859-1 et j’obtiens :
$ cat ambiguous
42¥
Je le configure maintenant en iso-8859-7 :
$ cat ambiguous
42₯
Ainsi, selon l’encodage je peux parler d’un prix en devise japonaise ou en devise grecque (avant l’euro) et impossible de trancher si je n’ai aucune idée duquel utiliser.
Outre le fait de devoir savoir quel encodage utiliser, il n’y a tout simplement pas la place pour représenter certains alphabets, comme par exemple, les langues utilisant des idéogrammes.
L’Unicode à la rescousse
Dans les années quatre-vingt-dix apparaît le standard Unicode, celui-ci cherche à rassembler tous les caractères dans une seule norme. Il contient quelques cent vingt-huit mille caractères. Le principe est simple, un nombre correspond à un symbole, point.
Ces nombres, appelés point de code sont représentés en hexadécimal. Ainsi, le symbole latin a a pour point de code U+0061 et le symbole grec Ω a pour point de code U+03A9. Ceux-ci sont agencés en plans, les plus utilisés étant le “plan 0 : Basic Multilingual Plane” et le “plan 1 : Supplementary Multilingual Plane”.
Maintenant, comment encoder ces symboles qui ne peuvent tenir sur un octet ? Faisons au plus simple : prenons notre symbole, trouvons son point de code, écrivons-le sur autant d’octets que nécessaire, et recommençons avec le symbole suivant.
Je vous propose la séquence d’octets suivante 61 62 63, pouvez-vous me reconstituer la phrase ?
Bien sûr que non ! Cette suite pourrait correspondre à bien des choses :
abc
慢c
a扣
Il faut trouver un moyen de représenter n’importe quel caractère sans ambiguïté !
UTF-8, UTF-16 et UTF-32
Avant toute chose, sachez que ces trois encodages permettent de représenter l’ensemble des caractères Unicode. (Donc ne faites pas mon erreur de penser que l’UTF-32 peut représenter plus de caractère que l’UTF-16 qui lui-même peut représenter plus de caractères que l’UTF-8 😅)
La “seule” différence, est la façon d’agencer les zéros et les uns.
UTF-32
Le plus simple des trois, l’UTF-32 représente chaque caractère sur quatre octets ! À la manière d’un fichier ASCII, ici nous lisons le fichier quatre octets par quatre octets.
# terminal en utf32
$ echo -ne '\x00\x00\x00\x61\x00\x00\x62\x63' > utf32
$ cat utf32
a扣
$ echo -ne '\x00\x00\x00\x61\x00\x00\x00\x62\x00\x00\x00\x63' > utf32b
$ cat utf32b
abc
Aucune ambiguïté possible. Seulement voilà, les caractères qui auparavant tenaient sur un octet, en occupent quatre maintenant, une énorme perte de place !
UTF-16
Cet encodage permet de faire tenir tout caractère sur un codet (deux octets) ou un demi-codet (deux fois deux octets) (oui ce n’est pas logique).
Les caractères du plan zéro sont représenté sur un codet. Pour les caractères de plan supérieur, nous les représentons sur un demi-codet et devons utiliser les demi-zones d’indirection. Ces zones regroupent tous les codets dont les cinq bits de poids fort sont 11011.
Pour encoder les caractères sur un demi-codet nous utilisons la procédure suivante :
- soustraire au point de code la valeur
0x10000; - prendre les dix bits de poids fort et y pré-fixer
1101 10; - prendre les dix bits de poids faible et y pré-fixer
1101 11.
Exemple pour 😀 :
0000 1111 0110 0000 0000 # 0x1F600 - 0x10000
fort = 1101 1000 0011 1101 # 1101 10 + 0000 1111 01
faible = 1101 1110 0000 0000 # 1101 11 + 10 0000 0000
1101 1000 0011 1101 1101 1110 0000 0000 # demi-codet
D8 3D DE 00 # en hexadécimal
Et vérifions avec :
# terminal en utf16
$ echo -ne '\xD8\x3D\xDE\x00' > utf16
$ cat utf16
😀
Simple n’est-ce pas ? Et si nous pouvions faire encore mieux ?
UTF-8
Ce dernier encodage permet de représenter tous les caractères sur un à quatre octets :
- de
U+0000àU+007Fil faut un octet ; - de
U+0080àU+07FFil faut deux octets ; - de
U+0800àU+FFFFil faut trois octets ; - à partir de
U+10000il faut quatre octets.
Pour l’encodage, nous nous référons à cette liste2 :
0x00000000 - 0x0000007F:
0xxxxxxx
0x00000080 - 0x000007FF:
110xxxxx 10xxxxxx
0x00000800 - 0x0000FFFF:
1110xxxx 10xxxxxx 10xxxxxx
0x00010000 - 0x001FFFFF:
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
Il nous suffit de substituer les x par le code binaire, en commençant par les bits de poids faible.
Reprenons notre caractère 😀. Pour l’encoder en UTF-8 nous faisons :
00 011111 011000 000000 # point de code en binaire
11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
11110x00 10011111 10011000 10000000 # substitution
11110000 10011111 10011000 10000000 # tous les x restants en 0
F0 9F 98 80 # en hexadécimal
Vérifions avec :
# terminal en utf8
$ echo -ne '\xF0\x9F\x98\x80' > utf8
$ cat utf8
😀
Encore plus simple vous ne trouvez pas ? Cet encodage a plusieurs avantages. Il gaspille moins de place que les deux autres et il est compatible avec la table ASCII.
Détection de l’encodage
Jusqu’à présent nous devions préciser quel encodage utiliser pour afficher les séquences de textes. Mais, en avons-nous vraiment besoin ?
Utilisons la commande *nix file qui permet de détecter l’encodage d’un fichier.
Testons sur nos séquences précédentes.
$ file ascii
ASCII text
$ file utf32
data
$ file utf16
ISO-8859 text
$ file utf8
UTF-8 Unicode text
Seulement deux encodages sont reconnus 😱 La divination ne marche pas toujours. Pour être sûr, nous avons systématiquement besoin de spécifier l’encodage. Ceci n’est vraiment pas ergonomique.
Existe-t-il un moyen de spécifier cet encodage qui soit transparent à l’utilisateur ?
L’indicateur d’ordre des octets
Cet indicateur, appelé BOM en anglais, est une séquence de caractères placée en tête de fichier qui permet de spécifier l’encodage. Il s’agit d’un nombre magique. Il est présent dans le corps du fichier, mais les logiciels ne doivent pas le gérer en tant que caractère, mais en tant qu’information (à la manière d’une métadonnée).
En voici une liste (non-exhaustive) :
- UTF-8 :
EF BB BF; - UTF-16 :
FE FF; - UTF-32 :
00 00 FE FF.
Testons cela.
$ echo -ne '\x00\x00\xFE\xFF\x00\x00\x00\x61\x00\x00\x62\x63' > utf32
$ echo -ne '\xFE\xFF\xD8\x3D\xDE\x00' > utf16
$ echo -ne '\xEF\xBB\xBF\xF0\x9F\x98\x80' > utf8
Vérifions avec :
$ file utf32
UTF-32 Unicode text
$ file utf16
UTF-16 Unicode text
$ file utf8
UTF-8 Unicode text (with BOM)
Tout fonctionne !
Cependant, comment faire pour traiter des flux de données ? Et bien il n’y a pas de solution miracle. Il faut encore spécifier manuellement l’encodage.
Au final
Quel encodage devons-nous utiliser ?
Et bien il n’y a pas de réponse.
Par exemple les langages Java et JavaScript utilisent de l’UTF-16 pour les chaînes de caractères, le langage Rust de l’UTF-8. Microsoft utilise de l’UTF-32 avec indicateur. Les systèmes *nix utilisent de l’UTF-8 et de l’UTF-32. Le web repose sur l’UTF-8.
Aujourd’hui, le monde informatique tend à privilégier l’UTF-8. À vous de voir ce qui convient le mieux pour vos besoins.
Références :
- Convertisseur de code Unicode
- UTF-8, UTF-16, UTF-32 & BOM
- Manually converting unicode codepoints into UTF-8 and UTF-16
- Character Sets